
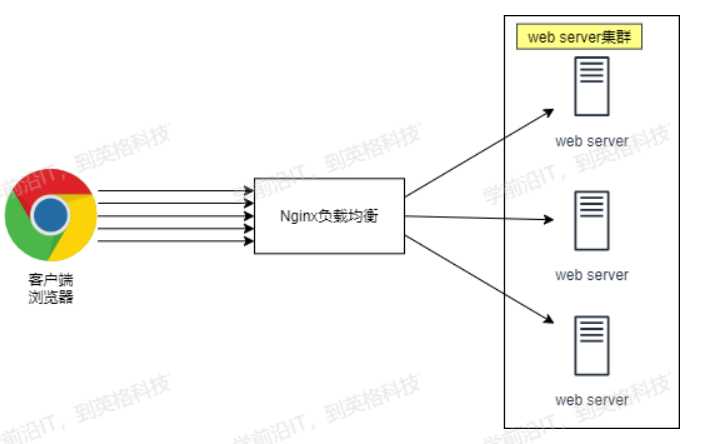
当我们只有一台服务器的话,全球各地的用户都访问这台服务器,会导致服务器承受不了如此巨大的请求而崩掉,所以我们引入了负载均衡服务器,我们可以搭建很多的服务器放同样的网页资源,组成一个服务器集群,然后前面放一个负载均衡服务器,当客户端访问服务器时,负载均衡服务器会把客户端的请求分发给web server集群中的一个服务器来处理。会大幅度提高网站的容灾,吞吐量,访问速度,效率等。
负载均衡
load balance LB nginx就是一个典型的SLB
四层负载均衡
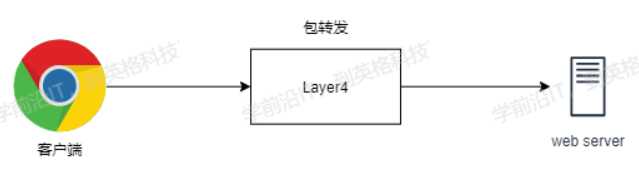
四层对应的是OSI模型中的传输层,利用的是传输层中的TCP/IP协议对客户端进行转发包请求,优点就是性能快,但速度没有七层快
七层负载均衡

七层在OSI模型中对应应用层,那么它可以完成很多应用方面的协议请求,比如我们说的http应用的负载均衡,它可以实现http信息的改写、头信息的改写、安全应用规则控制、URL匹配规则控制、以及转发、rewrite等等的规则,所以在应用层的服务里面,我们可以做的内容就更多,那么Nginx则是一个典型的七层负载均衡SLB
区别
七层活跃于最顶层,四层在下面,所以七层效率没有四层高
但七层在应用层,可以完成很多协议,更贴近于http服务,例如http协议的转发,会话保持,URL规则的匹配,head头改写等
七层可以识别域名
负载均衡使用场景
nginx负载均衡要使用到proxy_pass模块
nginx负载均衡和代理的区别是代理用的是location只能处理一台服务器,相反负载是把客户端的请求转发给upstream服务池来处理

实验准备
LB01 192.168.208.10
server1 192.168.208.20
server2 192.168.208.30
server1上
[root@web01 ~]# cd /etc/nginx/conf.d/
[root@web01 conf.d]# vim node.conf
server {
listen 80;
server_name node.test.com;
location / {
root /code/node;
index index.html;
}
}
[root@web01 conf.d]# mkdir -p /code/node
[root@web01 conf.d]# echo "web01 ..." > /code/node/index.html
[root@web01 conf.d]# systemctl restart nginx
server2上
[root@web02 ~]# cd /etc/nginx/conf.d/
[root@web02 conf.d]# vim node.conf
server {
listen 80;
server_name node.test.com;
location / {
root /code/node;
index index.html;
}
}
[root@web02 conf.d]# mkdir -p /code/node
[root@web02 conf.d]# echo "web02 ..." > /code/node/index.html
[root@web02 conf.d]# systemctl restart nginx
LB01上
[root@lb01 ~]# cd /etc/nginx/conf.d/
[root@lb01 conf.d]# vim /etc/nginx/proxy_params
proxy_set_header Host http_host;
proxy_set_header X-Real-IPremote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_connect_timeout 30;
proxy_send_timeout 60;
proxy_read_timeout 60;
proxy_buffering on;
proxy_buffer_size 32k;
proxy_buffers 4 128k;
[root@lb01 conf.d]# vim node_proxy.conf
upstream node {
server 192.168.208.20:80;
server 192.168.208.30:80;
}
server {
listen 80;
server_name node.test.com;
location / {
proxy_pass http://node;
include proxy_params;
}
}
[root@lb01 conf.d]# nginx -t
[root@lb01 conf.d]# systemctl restart nginx
访问
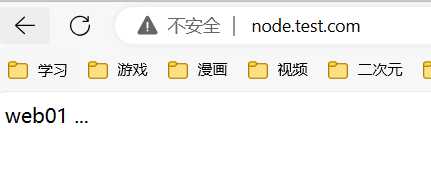
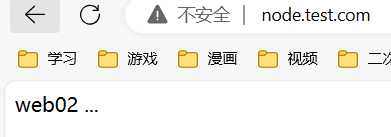
负载均衡典型错误分析
如果后台服务连接超时,Nginx是本身是有机制的,如果出现一个节点down掉的时候,Nginx会更据你具体负载均衡的设置,将请求转移到其他的节点上,但是,如果后台服务连接没有down掉,但是返回错误异常码了如:504、502、500,这个时候你需要加一个负载均衡的设置,如下:proxy_next_upstream http_500 | http_502 | http_503 | http_504 |http_404;意思是,当其中一台返回错误码404,500...等错误时,可以分配到下一台服务器程序继续处理,提高平台访问成功率。
server {
listen 80;
server_name node.test.com;
location / {
proxy_pass http://node;
proxy_next_upstream error timeout http_500 http_502 http_503 http_504 http_404;
}
}
nginx负载均衡调度算法
默认是轮询,按照时间顺序逐一分发到不同服务器
weight 加权轮询,谁的weight大 机会就多
ip_hash 来自同一ip的固定访问一个后端服务器
url_hash 每个url定向到同一个后端服务器
least_conn 最少链接数 哪个链接数少就分发
轮询
upstream load_pass {
server 192.168.175.10:80;
server 192.168.175.20:80;
}
加权轮询
upstream load_pass {
server 192.168.175.10:80 weight=5;
server 192.168.175.20:80;
}
ip_hash
#不能和weight一起用
#如果客户端都走相同代理, 会导致某一台服务器连接过多
upstream load_pass {
ip_hash;
server 192.168.175.10:80;
server 192.168.175.20:80;
}
nginx负载均衡后端状态

nginx负载均衡健康检查
依赖nginx_upstream_check_module模块
安装
[root@lb01 ~]# yum install -y gcc glibc gcc-c++ pcre-devel openssl-devel patch unzip wget #依赖包
[root@lb01 ~]# cd ~
[root@lb01 ~]# wget https://nginx.org/download/nginx-1.14.2.tar.gz
[root@lb01 ~]# wget https://github.com/yaoweibin/nginx_upstream_check_module/archive/master.zip
[root@lb01 ~]# tar xf nginx-1.14.2.tar.gz
[root@lb01 ~]# unzip master.zip
#关闭原来yum装的nginx
[root@lb01 ~]# systemctl stop nginx
[root@lb01 ~]# cd nginx-1.14.2
[root@lb01 nginx-1.14.2]# ./configure --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/run/nginx.lock --http-client-body-temp-path=/var/cache/nginx/client_temp --http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp --user=nginx --group=nginx --with-compat --with-file-aio --with-threads --with-http_addition_module --with-http_auth_request_module --with-http_dav_module --with-http_flv_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_mp4_module --with-http_random_index_module --with-http_realip_module --with-http_secure_link_module --with-http_slice_module --with-http_ssl_module --with-http_stub_status_module --with-http_sub_module --with-http_v2_module --with-mail --with-mail_ssl_module --with-stream --with-stream_realip_module --with-stream_ssl_module --with-stream_ssl_preread_module --add-module=/root/nginx_upstream_check_module-master --with-cc-opt='-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -fPIC' --with-ld-opt='-Wl,-z,relro -Wl,-z,now -pie'
[root@lb01 ~]# cd /root/nginx-1.14.2
[root@lb01 ~]# patch -p1 < /root/nginx_upstream_check_module-master/check_1.14.0+.patch
[root@lb01 nginx-1.14.2]# make && make install
[root@lb01 nginx-1.14.2]# nginx -v
nginx version: nginx/1.14.2
在已有的负载均衡上增加健康检查的功能
[root@lb01 conf.d]# vim /etc/nginx/conf.d/proxy_web.conf
upstream node {
server 192.168.175.20:80;
server 192.168.175.30:80;
check interval=3000 rise=2 fall=3 timeout=1000 type=tcp;
#interval 检测间隔时间,单位为毫秒
#rise 表示请求2次正常,标记此后端的状态为up
#fall 表示请求3次失败,标记此后端的状态为down
#type 类型为tcp
#timeout 超时时间,单位为毫秒
}
server {
listen 80;
server_name node.test.com;
location / {
proxy_pass http://node;
include proxy_params;
}
location /upstream_check {
check_status;
}
}
抓包可以看到周期性的进行tcp syn检测连接状态
也可以改为用http类型去检测,type修改为http
check interval=3000 rise=2 fall=3 timeout=1000 type=http;
nginx负载均衡会话保持
两种方式 一种用ip_hash模块 根据客户端的hash值给分配到固定的服务端,另一种是session会话共享,memcache,redis,mysql,nfs都可以做会话共享。
什么是cookie?什么是session?
cookie是客户端浏览器存的用户信息,包括登录状态,用户名密码等,客户端浏览器发送请求给服务端,服务端会根据这个cookie到session库里找到对应的值进行匹配,如果匹配成功,返回给客户端就可以访问了
会话保持配置
[root@web01 ~]# vim /etc/nginx/conf.d/php.conf
server {
listen 80;
server_name php.test.com;
root /code/phpMyAdmin-4.8.4-all-languages;
location / {
index index.php index.html;
}
location ~ \.php{
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAMEdocument_rootfastcgi_script_name;
include fastcgi_params;
}
}
[root@web01 ~]# nginx -t
[root@web01 ~]# systemctl restart nginx
[root@web02 ~]# vim /etc/nginx/conf.d/php.conf
server {
listen 80;
server_name php.test.com;
root /code/phpMyAdmin-4.8.4-all-languages;
location / {
index index.php index.html;
}
location ~ \.php {
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME document_rootfastcgi_script_name;
include fastcgi_params;
}
}
[root@web02 ~]# nginx -t
[root@web02 ~]# systemctl restart nginx
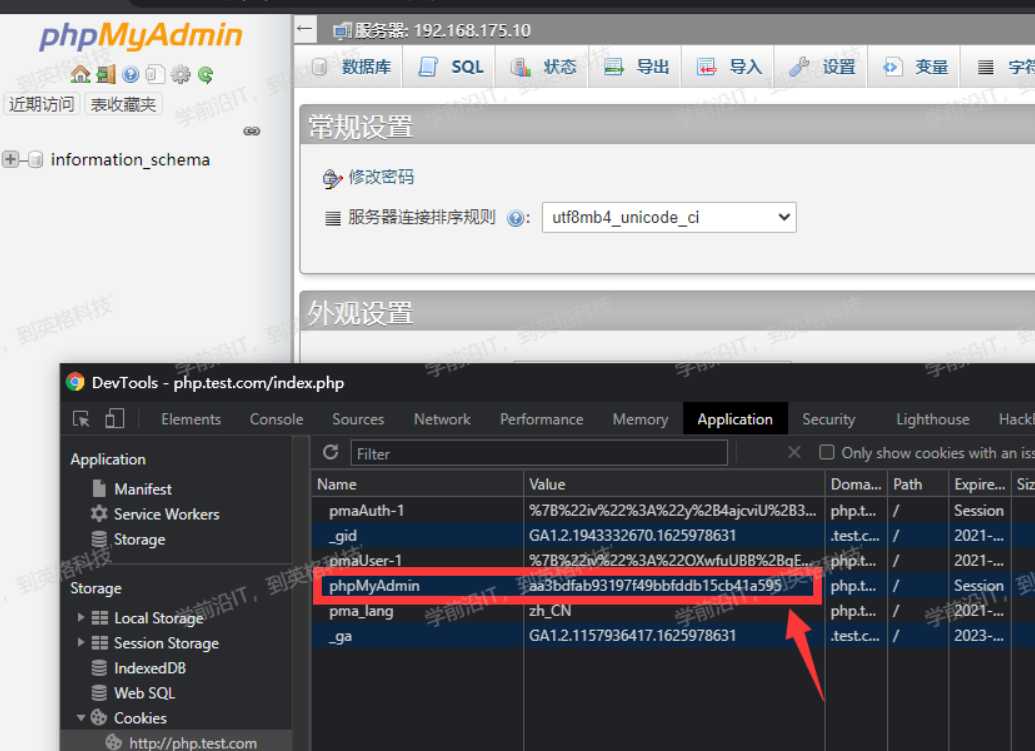
查看服务器上的session
[root@web01 ~]# ll /var/lib/php/session/
总用量 4
-rw------- 1 nginx nginx 2625 7月 11 20:08 sess_aa3bdfab93197f49bbfddb1
将web01上配置好的phpmyadmin以及nginx的配置文件推送到web02主机上
[root@web01 code]# scp -rp phpMyAdmin-4.8.4-all-languages root@192.168.175.30:/code/
[root@web01 code]# scp /etc/nginx/conf.d/php.conf root@192.168.175.30:/etc/nginx/conf.d/
在web02上重启Nginx服务
[root@web02 ~]# systemctl restart nginx
在web02上配置权限
[root@web02 ~]# chown -R nginx.nginx /var/lib/php/
接入负载均衡
[root@lb01 ~]# vim /etc/nginx/conf.d/proxy_php.com.conf
upstream php {
server 192.168.175.20:80;
server 192.168.175.30:80;
}
server {
listen 80;
server_name php.test.com;
location / {
proxy_pass http://php;
include proxy_params;
}
}
[root@lb01 ~]# nginx -t
[root@lb01 ~]# systemctl restart nginx
使用负载均衡的轮询功能之后,会发现,如果将session保存在本地文件的话,永远都登录不上去。
使用redis实现会话共享
安装redis数据库
[root@lb01 ~]# redis-cli -a centos
php配置session连接redis
[root@web01 ~]# vim /etc/php.ini
session.save_handler = redis
session.save_path = "tcp://192.168.175.10:6379"
;session.save_path = "tcp://192.168.175.10:6379?auth=centos" #如果redis存在密码,则使用该方式
session.auto_start = 1 #开启session.auto_start的优点在于,任何时候都不会因忘记执行session_start()或session_start()在程序里的位置不对,而导致错误;缺点在于,如果你使用的是第三方代码,则必须删去其中的全部 session_start(),否则将不能得到正确的结果。
[root@web01 ~]# vim /etc/php-fpm.d/www.conf
#注释php-fpm.d/www.conf里面的两条内容,否则session内容会一直写入/var/lib/php/session目录中
;php_value[session.save_handler] = files
;php_value[session.save_path] = /var/lib/php/session
重启php-fpm nginx
[root@web01 ~]# systemctl restart php-fpm
[root@web01 ~]# systemctl restart nginx
将web01上配置好的文件推送到web02
[root@web01 ~]# scp /etc/php.ini root@192.168.175.30:/etc/php.ini
[root@web01 ~]# scp /etc/php-fpm.d/www.conf root@192.168.175.30:/etc/php-fpm.d/www.conf
在web02上重启php-fpm nginx
[root@web02 ~]# systemctl restart php-fpm
[root@web02 ~]# systemctl restart nginx
redis查看数据
[root@lb01 ~]# redis-cli -a centos
127.0.0.1:6379> keys *
1) "PHPREDIS_SESSION:7e772fe37b1488069e3c54e419df7eda"
高可靠性
一个七层SLB崩掉的话会web导致服务器,所以我们有SLB集群,然后每个SLB分配负载的主机,如果其中一个崩掉了,四层负载均衡来进行介入协调分配负载给其他的SLB,无法访问七层负载均衡存在高可靠性问题,可以用四层负载均衡顶在前面解决这个问题,而四层需要keepalived或者LVS来保持自己的高可靠性
nginx如何配置四层负载均衡
LB的5555端口映射到20的mysql 3306
LB的6666端口映射到30的 22
#配置
vim /etc/nginx/nginx.conf
include /etc/nginx/conf.c/*.conf;
mkdir /etc/nginx/conf.c/
vim /etc/nginx/conf.c/lb_proxy.conf
stream {
upstream lb {
server 192.168.208.20:80 weight=5 max_fails=3 fail_timeout=30s;
server 192.168.208.30:80 weight=5 max_fails=3 fail_timeout=30s;
}
server {
listen 8080;
proxy_connect_timeout 3s;
proxy_timeout 3s;
proxy_pass lb;
}
}
### 访问日志,四层负载均衡访问日志是在http模块下面的,而四层负载均衡配置在http外面,所以如果需要访问日志,需要在stream后面
```bash
[root@lb01 ~]# cd /etc/nginx/conf.c/
[root@lb01 conf.c]# vim lb_domain.conf
stream {
log_format proxy 'remote_addrremote_port - [time_local]status protocol '
'"upstream_addr" "upstream_bytes_sent" "upstream_connect_time"';
access_log /var/log/nginx/proxy.log proxy;
upstream lb {
server 192.168.175.20:80 weight=5 max_fails=3 fail_timeout=30s;
server 192.168.175.30:80 weight=5 max_fails=3 fail_timeout=30s;
}
server {
listen 8080;
proxy_connect_timeout 3s;
proxy_timeout 3s;
proxy_pass lb;
}
}
[root@lb01 conf.c]# nginx -t
[root@lb01 conf.c]# systemctl restart nginx
浏览器访问查看日志
tailf /var/log/nginx/proxy.log
nginx四层负载均衡端口转发
四层可以用来实行tcp的转发
请求负载均衡 5555 ---> 192.168.208.20:22;
请求负载均衡 6666 ---> 192.168.208.30:3306;
配置实现tcp转发
[root@lb01 ~]# vim /etc/nginx/conf.c/lb_domain.conf
stream {
log_format proxy 'remote_addrremote_port - [time_local]status protocol '
'"upstream_addr" "upstream_bytes_sent" "upstream_connect_time"' ;
access_log /var/log/nginx/proxy.log proxy;
#定义转发ssh的22端口
upstream ssh {
server 192.168.175.20:22;
}
#定义转发mysql的3306端口
upstream mysql {
server 192.168.175.30:3306;
}
server {
listen 5555;
proxy_connect_timeout 3s;
proxy_timeout 300s;
proxy_pass ssh;
}
server {
listen 6666;
proxy_connect_timeout 3s;
proxy_timeout 3s;
proxy_pass mysql;
}
}
[root@lb01 ~]# nginx -t
[root@lb01 ~]# systemctl restart nginx
测试
使用xshell测试ssh
ssh root@192.168.175.10 5555
命令行测试mysql连接
[root@web02 conf.d] # mysql -uroot -p123456 -h192.168.175.10 -P6666 -e"select user,host from mysql.user;"
keepalived实现四层负载均衡高可用
两台机器启动着相同的业务,如果一台服务器down掉之后,keepalived会自动切换另一台机器来完成请求的转发,这个过程速度很快,客户很难察觉
keepalived基于ARRP协议实现的
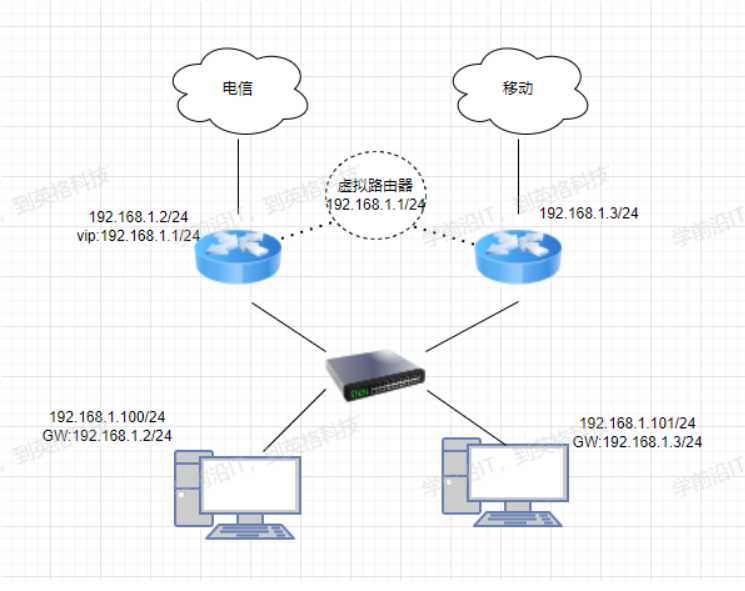
什么是ARRP协议呢?
所谓的ARRP协议其实就是一种容错的主备模式的协议,会有一个主路由器和一个副路由器,主路由器平时正常工作接受转发消息,然后会有一个虚拟路由器产生一个虚拟ip 叫vip 这个vip会漂移,这个虚拟ip是固定的,假如主路由器down掉了,会给副路由器发消息副路由器反客为主,然后vip会自动漂移到副路由器上,VRRP协议解决了单点故障问题,客户端只要访问这个虚拟ip地址就行,其他的不用管。当然如果有很多的副路由器,主路由器挂掉了,内部会选举出一个来当主人,怎么选,他是有一个内部机制的,分为抢占式和非抢占式,抢占式就是你优先级高,你进来了,正在当主人的得把位置让给你,非抢占式的,你优先级高,但现在有人在当主人,你只能等他挂了,你才能当上主人。
keepalived安装配置
安装keepalived
[root@lb01 ~]# yum install -y keepalived
[root@lb02 ~]# yum install -y keepalived
配置master
找到配置文件
[root@lb02 ~]# rpm -qc keepalived
/etc/keepalived/keepalived.conf
/etc/sysconfig/keepalived
修改配置
[root@lb01 ~]# vim /etc/keepalived/keepalived.conf
global_defs { #全局配置
router_id lb01 #标识身份->名称
}
vrrp_instance VI_1 {
state MASTER #标识角色状态
interface ens33 #网卡绑定接口
virtual_router_id 50 #虚拟路由id
priority 150 #优先级
advert_int 1 #监测间隔时间
#use_vmac #使用虚拟mac地址,因为路由问题,可能导致原本的IP不可用
authentication { #认证
auth_type PASS #认证方式
auth_pass 1111 #认证密码
}
virtual_ipaddress {
192.168.208.100 #虚拟的VIP地址
}
}
配置backup
[root@lb02 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id lb02
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.208.100
}
}


启动master和backup节点的keepalived
[root@lb01 ~]# systemctl start keepalived
[root@lb01 ~]# systemctl enable keepalived
[root@lb02 ~]# systemctl start keepalived
[root@lb02 ~]# systemctl enable keepalived
keepalived抢占式与非抢占式详解
由于节点1的优先级高于节点2所以vip虚拟ip会在lb01上面
lb01 ip a|grep 192.168.208.100
关闭节点1的keepalived
systemctl stop keepalived
节点2搜索不到节点1了,自动接管vip
lb02 ip a
因为配置的是抢占式的所以当节点一起来之后 vip又飘到了节点一上面来了
[root@lb01 ~]# systemctl start keepalived
[root@lb01 ~]# ip addr |grep 192.168.175.100
inet 192.168.175.100/32 scope global ens33
配置非抢占式的
两个节点必须都配置成backup备份路由器,配置nopreempt,唯一的区别就是一个优先级高一个优先级低。
[root@lb01 ~]# systemctl start keepalived
[root@lb01 ~]# ip addr |grep 192.168.175.100
inet 192.168.208.100/32 scope global ens33
Master配置
vrrp_instance VI_1 {
state BACKUP #修改为BACKUP
priority 150
nopreempt #加上这行
}
Backup配置
vrrp_instance VI_1 {
state BACKUP
priority 100
nopreempt #加上这行
}
systemctl restart keepalived
通过windows arp验证看是否会切换mac地址
# 当前master在lb01上
[root@lb01 ~]# ip addr |grep 192.168.208.100
inet 192.168.175.100/32 scope global ens33
# windows查看mac地址
C:\Users\Aaron>arp -a |findstr 192.168.208.100
192.168.208.100 00-0c-29-bb-9a-49 动态
# 关闭lb01的keepalive
[root@lb01 ~]# systemctl stop keepalived
#lb02接管vIP
[root@lb02 ~]# ip addr |grep 192.168.208.100
inet 192.168.208.100/32 scope global ens33
#再次查看windows的mac地址
C:\Users\Aaron>arp -a |findstr 192.168.208.100
192.168.208.100 00-0c-29-bb-9a-bb 动态
keepalived脑裂
出于一些原因,可能会出现两个高可用服务器无法互相进行心跳检测,这时候双方都以为对面挂了,都变成master了
出现的原因
服务器网线松动
服务器硬件出现故障
两边开启了防火墙 把对面给ban掉了
正常情况下 我这边的lb02是master 我们用wireshark进行抓包会发现只有lb02在处理转发请求

但是如果我们两边开启防火墙呢?
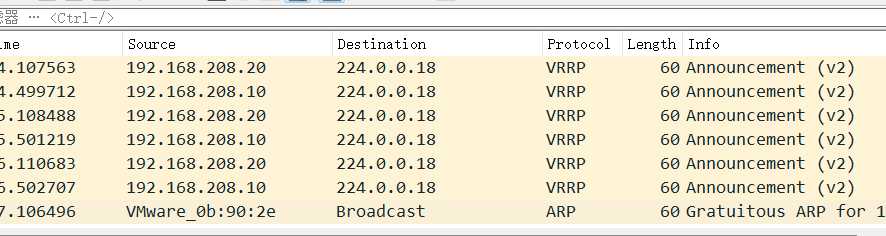
通过抓包软件两个服务器互相竞争者这个master
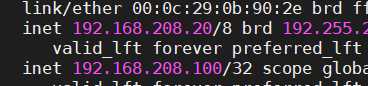
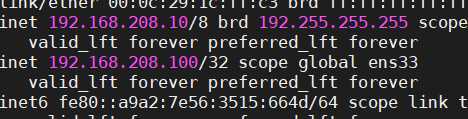
两边都有这个虚拟的vip 都想当主人 这就导致了脑裂
具体解决方法,可以检测下防火墙,看看网线,更新自己的服务器硬件之类的来解决这些问题
或者把其中一个kill掉
我们可以编写一个脚本
在backup上编写检测脚本, 测试如果能ping通master并且backup节点还有vIP的话则认为产生了脑裂
[root@lb02 ~]# vim check_split_brain.sh
#!/bin/sh
vip=192.168.175.100
lb01_ip=192.168.175.10
while true;do
ping -c 2 lb01_ip &>/dev/null
if [? -eq 0 -a `ip add|grep "$vip"|wc -l` -eq 1 ];then
echo "ha is split brain.warning."
else
echo "ha is ok"
fi
sleep 5
done
测试:
在lb02运行好脚本后再打开lb02的防火墙,这时与lb01连接不上发生脑裂,脚本开始报错
高可用keepalived和nginx
前面我们只是说的keepalived挂掉了 我们的vip会自动漂移到被推举出来的一个BACKUP上,但是如果是nginx故障了呢?
显然nginx故障了,但是keepalived没有挂掉,vip不会漂移,用户访问这个nginx,就得不到想要的资源了,所以我们编写了一套脚本,用来检测nginx的存货状态,大致原理就是如果nginx挂了就自动kill掉keepalived
两台机器先装上nginx
yum install -y epel-release
yum install -y nginx
systemctl enable nginx --now
lb01:
echo "in lb01" > /usr/share/nginx/html/index.html
lb02:
echo "in lb02" > /usr/share/nginx/html/index.html
#访问192.168.208.100的效果就是in lb01,但是如果关闭lb01的keepalived,就变成in lb02
#但是如果nginx挂了,网页将会无法正常访问
我们来编写一下脚本
[root@lb01 ~]# vim check_web.sh
#!/bin/sh
nginxpid=(ps -C nginx --no-header|wc -l)
#1.判断Nginx是否存活,如果不存活则尝试启动Nginx
if [nginxpid -eq 0 ];then
systemctl start nginx
sleep 3
#2.等待3秒后再次获取一次Nginx状态
nginxpid=(ps -C nginx --no-header|wc -l) #3.再次进行判断, 如Nginx还不存活则停止Keepalived,让地址进行漂移,并退出脚本 if [nginxpid -eq 0 ];then
systemctl stop keepalived
fi
fi
[root@lb01 ~]# watch -n 5 "sh /root/check_web.sh"
集群和分布式
系统性能扩展有两种方式
一种是横向扩展 多买几个设备然后分别处理不同的业务来分担一个机器的压力
另一种纵向扩展 给机器换cpu 换硬件等来提高设备的性能,但这种方式要花的钱不说,性能也是有上限的
一般横向扩展采用的比较多
什么是集群?
顾名思义,把所有设备集中起来变成一个群体。比如说nginx搭建lvs集群就是多台服务器一样的配置运行同样的业务,提升了高可用性,将来如果有一台服务器挂掉了,另一台服务器能及时顶上来不会影响业务的发展
什么是分布式?
把各个业务分不开来,每台机器完成的任务不一样,整个业务最终是把所有机器的业务集合在一起进行汇总,大公司一般会分部门,什么销售部,运维部,人事部,司法部等,每个人完成的任务不同,但缺一不可,如果哪天人事部被敌对公司全部挖走了,那这个公司也就运行不起来了,一样的道理如果分布式有一个服务器坏掉了,那整个业务就崩掉了
LB Cluster
负载均衡集群
按照实现方式进行划分
1.硬件
F5 Big-IP
Citrix Netscaler
A10
2.软件
lvs
nginx
haproxy等
负载均衡的会话保持
1.ip_hash
同一用户调动不同服务器
2.每台机器拥有全部session
很显然不现实,资源消耗太高了,硬盘也要钱呀
3.session server
专门的session会话共享服务器 比如redis,memcached,当然redis也会存在单点问题,所以我们后面也会部署redis集群哨兵模式
LVS
lvs其实就是采用负载均衡技术将服务器组成一个集群 作用嘛 提高了服务器的高可用性
lvs工作原理
VS根据请求报文的目标IP和目标协议及端口将其调度转发至某RS,根据调度算法来挑选RS。LVS是内核级功能,工作在INPUT链的位置,将发往INPUT的流量进行“处理”
#查看内核支持lvs
[root@localhost ~]# grep -i -C 10 ipvs /boot/config-3.10.0-957.el7.x86_64
LVS实战
准备三台机器
[root@localhost ~]# yum ‐y install ipvsadm #远程ssh连接下使用这个命令会出bug,需要直接在虚拟机里使用命令
[root@localhost ~]# vim /usr/lib/systemd/system/ipvsadm.service
[Unit]
Description=Initialise the Linux Virtual Server
After=syslog.target network.target
[Service]
Type=oneshot
ExecStart=/bin/bash -c "exec /sbin/ipvsadm-restore < /etc/sysconfig/ipvsadm"
ExecStop=/bin/bash -c "exec /sbin/ipvsadm-save -n > /etc/sysconfig/ipvsadm"
ExecStop=/sbin/ipvsadm -C
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target
安装最好在虚拟机上进行,ssh远程连接安装可能会报错
ipvsadm命令
#管理集群服务
ipvsadm -A|E -t|u|f service-address [-s scheduler] [-p [timeout]] [-M netmask]
[--pe persistence_engine] [-b sched-flags]
ipvsadm -A #创建集群
ipvsadm -E #修改集群
ipvsadm -D -t|u|f service-address #删除
ipvsadm –C #清空
ipvsadm –R #重载
ipvsadm -S [-n] #保存
ipvsadm -L #查看
#管理集群中的RS
ipvsadm -a|e -t|u|f service-address -r server-address [options]
ipvsadm -d -t|u|f service-address -r server-address
ipvsadm -L|l [options]
ipvsadm -Z [-t|u|f service-address] #清空计数器
#保存规则
‐S
# ipvsadm ‐S > /path/to/somefile
载入此前的规则:
‐R
# ipvsadm ‐R < /path/form/somefile
# 说明
service-address:
-t|u|f:
-t: TCP协议的端口,VIP:TCP_PORT 如:-t 192.168.175.20:80
-u: UDP协议的端口,VIP:UDP_PORT 如:-u 192.168.175.20:80
-f:firewall MARK,标记,一个数字
[-s scheduler]:指定集群的调度算法,默认为wlc
server-address:
rip[:port] 如省略port,不作端口映射
选项:
lvs类型:
-g: gateway, dr类型,默认
-i: ipip, tun类型
-m: masquerade, nat类型
-w weight:权重
举例
ipvsadm -A -t 192.168.208.100:80 -s wrr
ipvsadm -D -t 192.168.208.100:80 #删除集群
-A 创建集群
-t 指定ip端口映射
-s 指定算法为加权轮询
ipvsadm -a -t 192.168.208.100:80 -r 192.168.208.20:8080 -m -w 3 # 往集群中添加RS,-m配置为nat模式,配置权重为3
ipvsadm -d -t 192.168.208.100:80 -r 192.168.208.20:8080 #删除集群
查看
ipvsadm -L|l [options]
–numeric, -n:以数字形式输出地址和端口号
–exact:扩展信息,精确值
–connection,-c:当前IPVS连接输出
–stats:统计信息
–rate :输出速率信息
lvs-nat模式案例:
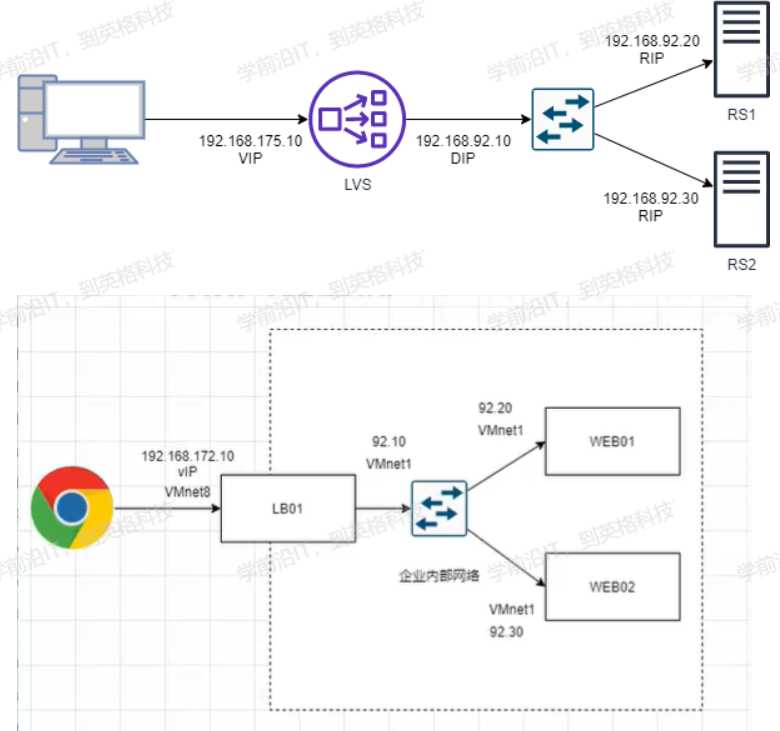
使用VMnet8做DR的网卡,给LB服务器添加一个VMmet1网卡,网卡设置为仅主机模式,后面的WEB01和WEB01服务器都把原来网卡的NAT模式切换为仅主机模式,模拟内网环境通过DR做NAT,以DR为网关来实现上网
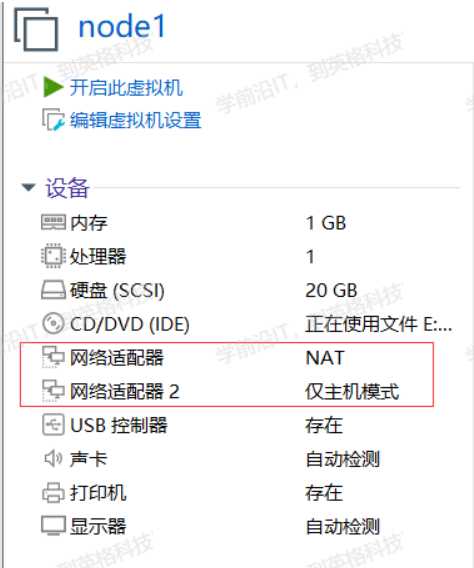
lb的仅主机网卡作为后面服务器的网关,后面两个服务器是仅主机模式,连不了外网的,后面配置让他们通过这个lb服务器连接外网


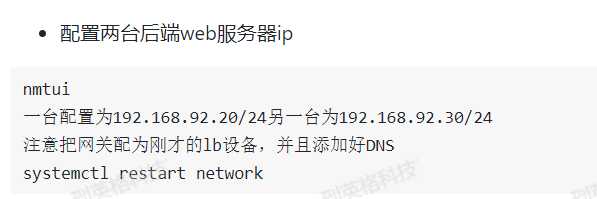
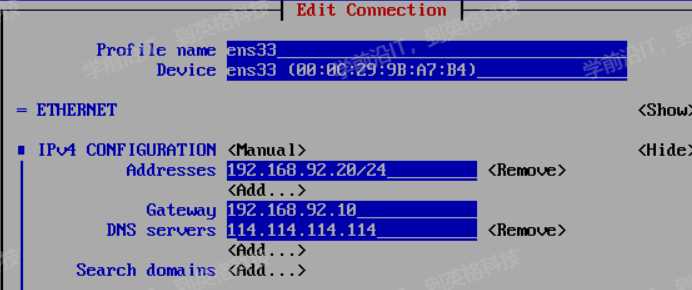
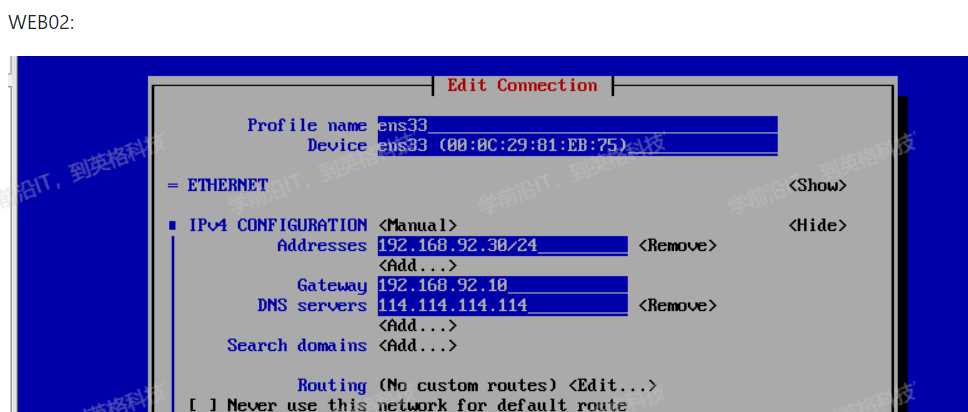
开启lvs流量转发并且配置NAT
[root@lvs ~]# vim /etc/sysctl.conf
net.ipv4.ip_forward = 1
[root@lvs ~]# sysctl -p
net.ipv4.ip_forward = 1
[root@lvs ~]# iptables -t nat -A POSTROUTING -s 192.168.92.0/24 -j MASQUERADE
[root@lvs ~]# iptables -t nat -L -n
#查看刚才配置的规则
先搭建web服务器
[root@rs1 ~]# yum -y install httpd
[root@rs1 ~]# systemctl start httpd
[root@rs1 ~]# systemctl enable httpd
[root@rs1 ~]# echo "RS1 ..." > /var/www/html/index.html
[root@rs1 ~]# firewall-cmd --add-service=http
[root@rs1 ~]# firewall-cmd --add-service=http --permanent
[root@rs2 ~]# yum -y install httpd
[root@rs2 ~]# systemctl start httpd
[root@rs2 ~]# systemctl enable httpd
[root@rs2 ~]# echo "RS2 ..." > /var/www/html/index.html
[root@rs2 ~]# firewall-cmd --add-service=http
[root@rs2 ~]# firewall-cmd --add-service=http --permanent
配置LVS
[root@lvs ~]# ipvsadm -A -t 192.168.175.10:80 -s rr #用192.168.175.10:80建一个集群用轮询的算法
[root@lvs ~]# ipvsadm -a -t 192.168.175.10:80 -r 192.168.92.20:80 -m #添加一个rs -m为nat模式
[root@lvs ~]# ipvsadm -a -t 192.168.175.10:80 -r 192.168.92.30:80 -m #再添加一个rs -m为nat模式
[root@lvs ~]# ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.175.100:80 rr
-> 192.168.92.20:80 Masq 1 0 0
-> 192.168.92.30:80 Masq 1 0 0
HAProxy
c语言开发 外国大佬 开源免费 作用 实现负载均衡 提高了高可用性 tcp/udp的代理
企业版:https://www.haproxy.com/
社区版:https://www.haproxy.org/
编译安装haproxy
更多源码:https://www.haproxy.org/download/
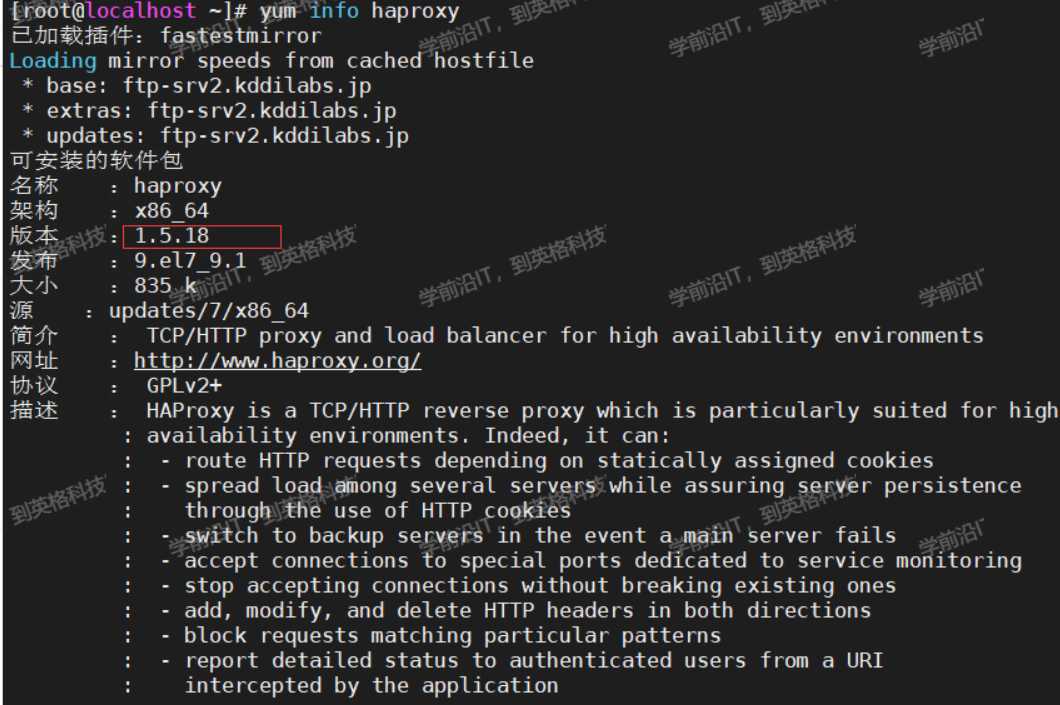
yum默认安装的是1.5的老版本
lua
lua是一款小众的脚本语言开发的程序,目的是为了嵌入应用程序,为应用程序提供更好的扩展性和定制功能
Lua 官网:www.lua.org
可用于游戏开发
独立应用脚本开发
web开发等
安装haproxy之前我们要先安装lua
安装基础命令已经编译依赖环境
[root@localhost ~]# yum -y install gcc readline-devel
[root@localhost ~]# wget http://www.lua.org/ftp/lua-5.3.5.tar.gz
[root@localhost ~]# tar xvf lua-5.3.5.tar.gz -C /usr/local/src
[root@localhost ~]# cd /usr/local/src/lua-5.3.5
[root@localhost lua-5.3.5]# make linux test
#查看编译安装的版本
[root@localhost lua-5.3.5]# src/lua -v
Lua 5.3.5 Copyright (C) 1994-2018 Lua.org, PUC-Rio
开始正式安装
#适用于1.8 1.9版本
make ARCH=x86_64 TARGET=linux2628 USE_PCRE=1 USE_OPENSSL=1 USE_ZLIB=1 USE_SYSTEMD=1 USE_CPU_AFFINITY=1 PREFIX=/usr/local/haproxy
HAProxy 2.0以上版本编译参数
[root@localhost ~]# yum -y install gcc openssl-devel pcre-devel systemd-devel
[root@localhost ~]# wget https://www.haproxy.org/download/2.1/src/haproxy-2.1.3.tar.gz
[root@localhost ~]# tar xvf haproxy-2.1.3.tar.gz -C /usr/local/src
[root@localhost ~]# cd /usr/local/src/haproxy-2.1.3/
[root@localhost haproxy-2.1.3]# cat README
编译安装
[root@localhost haproxy-2.1.3]# make ARCH=x86_64 TARGET=linux-glibc \
USE_PCRE=1 \
USE_OPENSSL=1 \
USE_ZLIB=1 \
USE_SYSTEMD=1 \
USE_LUA=1 \
LUA_INC=/usr/local/src/lua-5.3.5/src/ \
LUA_LIB=/usr/local/src/lua-5.3.5/src/
[root@localhost haproxy-2.1.3]# make install PREFIX=/apps/haproxy
[root@localhost haproxy-2.1.3]# ln -s /apps/haproxy/sbin/haproxy /usr/sbin/
查看生成的文件
[root@localhost ~]# tree -C /apps/haproxy/
/apps/haproxy/
├── doc
│ └── haproxy
│ ├── 51Degrees-device-detection.txt
│ ├── architecture.txt
│ ├── close-options.txt
│ ├── configuration.txt
│ ├── cookie-options.txt
│ ├── DeviceAtlas-device-detection.txt
│ ├── intro.txt
│ ├── linux-syn-cookies.txt
│ ├── lua.txt
│ ├── management.txt
│ ├── netscaler-client-ip-insertion-protocol.txt
│ ├── network-namespaces.txt
│ ├── peers.txt
│ ├── peers-v2.0.txt
│ ├── proxy-protocol.txt
│ ├── regression-testing.txt
│ ├── seamless_reload.txt
│ ├── SOCKS4.protocol.txt
│ ├── SPOE.txt
│ └── WURFL-device-detection.txt
├── sbin
│ └── haproxy
└── share
└── man
└── man1
└── haproxy.1
6 directories, 22 files
验证haproxy版本
[root@localhost ~]# which haproxy
/usr/sbin/haproxy
[root@localhost ~]# haproxy -v
HA-Proxy version 2.1.3 2020/02/12 - https://haproxy.org/
Status: stable branch - will stop receiving fixes around Q1 2021.
Known bugs: http://www.haproxy.org/bugs/bugs-2.1.3.html
[root@localhost ~]# haproxy -vv
HA-Proxy version 2.1.3 2020/02/12 - https://haproxy.org/
Status: stable branch - will stop receiving fixes around Q1 2021.
Known bugs: http://www.haproxy.org/bugs/bugs-2.1.3.html
Build options :
TARGET = linux-glibc
CPU = generic
CC = gcc
CFLAGS = -m64 -march=x86-64 -O2 -g -fno-strict-aliasing -Wdeclaration-after-statement -fwrapv -Wno-unused-label -Wno-sign-compare -Wno-unused-parameter -Wno-old-style-declaration -Wno-ignored-qualifiers -Wno-clobbered -Wno-missing-field-initializers -Wtype-limits
OPTIONS = USE_PCRE=1 USE_OPENSSL=1 USE_LUA=1 USE_ZLIB=1 USE_SYSTEMD=1
Feature list : +EPOLL -KQUEUE -MY_EPOLL -MY_SPLICE +NETFILTER +PCRE -PCRE_JIT -PCRE2 -PCRE2_JIT +POLL -PRIVATE_CACHE +THREAD -PTHREAD_PSHARED -REGPARM -STATIC_PCRE -STATIC_PCRE2 +TPROXY +LINUX_TPROXY +LINUX_SPLICE +LIBCRYPT +CRYPT_H -VSYSCALL +GETADDRINFO +OPENSSL +LUA +FUTEX +ACCEPT4 -MY_ACCEPT4 +ZLIB -SLZ +CPU_AFFINITY +TFO +NS +DL +RT -DEVICEATLAS -51DEGREES -WURFL +SYSTEMD -OBSOLETE_LINKER +PRCTL +THREAD_DUMP -EVPORTS
Default settings :
bufsize = 16384, maxrewrite = 1024, maxpollevents = 200
Built with multi-threading support (MAX_THREADS=64, default=4).
Built with OpenSSL version : OpenSSL 1.0.2k-fips 26 Jan 2017
Running on OpenSSL version : OpenSSL 1.0.2k-fips 26 Jan 2017
OpenSSL library supports TLS extensions : yes
OpenSSL library supports SNI : yes
OpenSSL library supports : SSLv3 TLSv1.0 TLSv1.1 TLSv1.2
Built with Lua version : Lua 5.3.5
Built with network namespace support.
Built with transparent proxy support using: IP_TRANSPARENT IPV6_TRANSPARENT IP_FREEBIND
Built with PCRE version : 8.32 2012-11-30
Running on PCRE version : 8.32 2012-11-30
PCRE library supports JIT : no (USE_PCRE_JIT not set)
Encrypted password support via crypt(3): yes
Built with zlib version : 1.2.7
Running on zlib version : 1.2.7
Compression algorithms supported : identity("identity"), deflate("deflate"), raw-deflate("deflate"), gzip("gzip")
Available polling systems :
epoll : pref=300, test result OK
poll : pref=200, test result OK
select : pref=150, test result OK
Total: 3 (3 usable), will use epoll.
Available multiplexer protocols :
(protocols marked as <default> cannot be specified using 'proto' keyword)
h2 : mode=HTTP side=FE|BE mux=H2
fcgi : mode=HTTP side=BE mux=FCGI
<default> : mode=HTTP side=FE|BE mux=H1
<default> : mode=TCP side=FE|BE mux=PASS
Available services : none
Available filters :
[SPOE] spoe
[CACHE] cache
[FCGI] fcgi-app
[TRACE] trace
[COMP] compression
haproxy启动脚本
[root@localhost ~]# vim /usr/lib/systemd/system/haproxy.service
[Unit]
Description=HAProxy Load Balancer
After=syslog.target network.target
[Service]
ExecStartPre=/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -c -q
ExecStart=/usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /var/lib/haproxy/haproxy.pid
ExecReload=/bin/kill -USR2 $MAINPID
[Install]
WantedBy=multi-user.target
默认缺少配置文件,无法启动
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl start haproxy
Job for haproxy.service failed because the control process exited with error code. See "systemctl status haproxy.service" and "journalctl -xe" for details.
[root@localhost ~]# tail /var/log/messages
Jul 13 10:39:33 localhost systemd: Starting HAProxy Load Balancer...
Jul 13 10:39:33 localhost haproxy: [ALERT] 193/103933 (8156) : Cannot open configuration file/directory /etc/haproxy/haproxy.cfg : No such file or directory
Jul 13 10:39:33 localhost systemd: haproxy.service: control process exited, code=exited status=1
Jul 13 10:39:33 localhost systemd: Failed to start HAProxy Load Balancer.
Jul 13 10:39:33 localhost systemd: Unit haproxy.service entered failed state.
Jul 13 10:39:33 localhost systemd: haproxy.service failed.
配置文件
创建自定义的配置文件
[root@localhost ~]# mkdir /etc/haproxy
[root@localhost ~]# vim /etc/haproxy/haproxy.cfg
global
maxconn 100000
chroot /apps/haproxy #锁定运行目录
stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin
#uid 99
#gid 99
user haproxy
group haproxy
daemon #以守护进程运行
#nbproc 4 #可以不写,不写默认为1,建议设成CPU个数
#cpu-map 1 0 #绑定haproxy worker 进程至指定CPU,将第1个work进程绑定至0号CPU
#cpu-map 2 1
#cpu-map 3 2
#cpu-map 4 3
pidfile /var/lib/haproxy/haproxy.pid
log 127.0.0.1 local2 info
defaults
option http-keep-alive
option forwardfor
maxconn 100000
mode http
timeout connect 300000ms
timeout client 300000ms
timeout server 300000ms
listen stats
mode http
bind 0.0.0.0:9999
stats enable
log global
stats uri /haproxy-status
stats auth admin:123456
listen web_port
bind 192.168.208.10:80
mode http
log global
server web1 127.0.0.1:8080 check inter 3000 fall 2 rise 5
启动
[root@localhost ~]# mkdir /var/lib/haproxy
[root@localhost ~]# useradd -r -s /sbin/nologin -d /var/lib/haproxy haproxy
[root@localhost ~]# systemctl enable --now haproxy
验证haproxy状态
aproxy.cfg文件中定义了chroot、pidfile、user、group等参数,如果系统没有相应的资源会导致haproxy无法启动,具体参考日志文件 /var/log/messages
[root@localhost ~]# systemctl status haproxy
● haproxy.service - HAProxy Load Balancer
Loaded: loaded (/usr/lib/systemd/system/haproxy.service; enabled; vendor preset: disabled)
Active: active (running) since 二 2021-07-13 10:45:39 CST; 38s ago
Process: 8360 ExecStartPre=/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg -c -q (code=exited, status=0/SUCCESS)
Main PID: 8363 (haproxy)
CGroup: /system.slice/haproxy.service
├─8363 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /var/lib/haproxy/hap...
└─8365 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /var/lib/haproxy/hap...
7月 13 10:45:39 localhost.localdomain systemd[1]: Starting HAProxy Load Balancer...
7月 13 10:45:39 localhost.localdomain systemd[1]: Started HAProxy Load Balancer.
7月 13 10:45:39 localhost.localdomain haproxy[8363]: [NOTICE] 193/104539 (8363) : New wor...d
7月 13 10:45:39 localhost.localdomain haproxy[8363]: [WARNING] 193/104539 (8365) : Server....
7月 13 10:45:39 localhost.localdomain haproxy[8363]: [ALERT] 193/104539 (8365) : proxy 'w...!
Hint: Some lines were ellipsized, use -l to show in full.
[root@lb01 haproxy-2.1.3]# pstree -p |grep haproxy
|-haproxy(7988)---haproxy(7992)
查看haproxy的状态页面
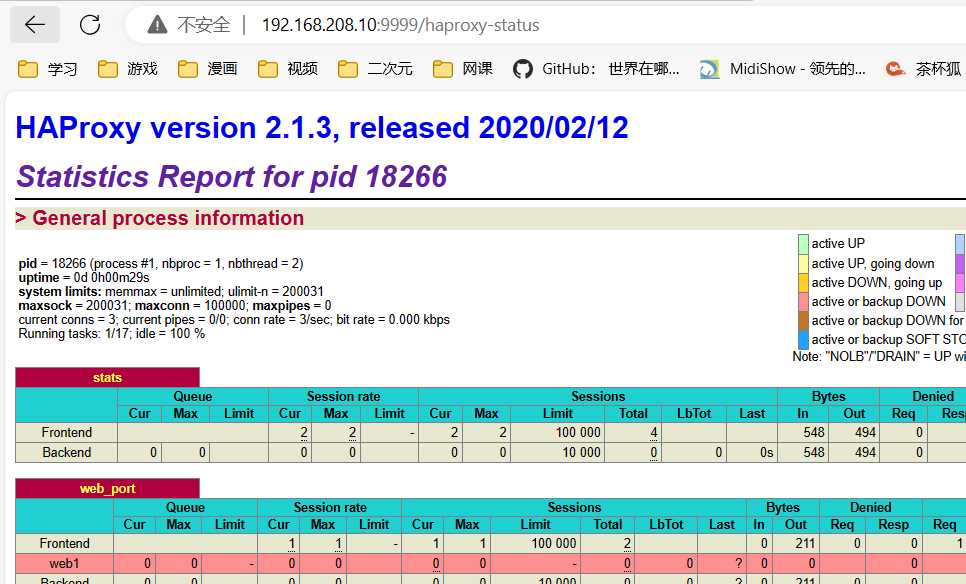
浏览器访问http://192.168.208.10:9999/haproxy-status
用户名admin,密码123456,这个是在配置文件里定义好的
haproxy基础配置详解
官方文档:https://cbonte.github.io/haproxy-dconv/2.1/configuration.htm
HAProxy 的配置文件haproxy.cfg由两大部分组成,分别是global和proxies部分
global:全局配置段
进程及安全配置相关的参数
性能调整相关参数
Debug参数
proxies:代理配置段
defaults:为frontend, backend, listen提供默认配置
frontend:前端,相当于nginx中的server {}
backend:后端,相当于nginx中的upstream {}
listen:同时拥有前端和后端配置
global配置
chroot #锁定运行目录
deamon #以守护进程运行
stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin process 1 #socket文件
user, group, uid, gid #运行haproxy的用户身份
nbproc n #开启的haproxy work 进程数,默认进程数是一个
#nbthread 1 #指定每个haproxy进程开启的线程数,默认为每个进程一个线程,和nbproc互斥(版本有关)
#如果同时启用nbproc和nbthread 会出现以下日志的错误,无法启动服务
Apr 7 14:46:23 haproxy haproxy: [ALERT] 097/144623 (1454) : config : cannot enable multiple processes if multiple threads are configured. Please use either nbproc or nbthread but not both.
cpu-map 1 0 #绑定haproxy 进程至指定CPU,将第一个work进程绑定至0号CPU
maxconn n #每个haproxy进程的最大并发连接数
maxsslconn n #每个haproxy进程ssl最大连接数,用于haproxy配置了证书的场景下
maxconnrate n #每个进程每秒创建的最大连接数量
spread-checks n #后端server状态check随机提前或延迟百分比时间,建议2-5(20%-50%)之间,默认值0
pidfile #指定pid文件路径
log 127.0.0.1 local2 info #定义全局的syslog服务器;日志服务器需要开启UDP协议,最多可以定义两个
多进程和线程
[root@localhost ~]# vim /etc/haproxy/haproxy.cfg
global
maxconn 100000
chroot /apps/haproxy
stats socket /var/lib/haproxy/haproxy.sock1 mode 600 level admin process 1
stats socket /var/lib/haproxy/haproxy.sock2 mode 600 level admin process 2
user haproxy
group haproxy
daemon
nbproc 2
[root@localhost ~]# systemctl restart haproxy
[root@localhost ~]# pstree -p |grep haproxy
|-haproxy(8395)-+-haproxy(8399)
| `-haproxy(8400)
[root@localhost ~]# ll /var/lib/haproxy/
总用量 4
-rw-r--r--. 1 root root 5 7月 13 10:56 haproxy.pid
srw-------. 1 root root 0 7月 13 10:56 haproxy.sock1
srw-------. 1 root root 0 7月 13 10:56 haproxy.sock2
日志配置
HAProxy配置
# 在global配置项定义
log 127.0.0.1 local{1-7} #基于syslog记录日志到指定设备,级别有(err、warning、info、debug),在1-7中选择一个等级
#emerg 0 系统不可用 alert 1 必须马上采取行动的事件 crit 2 关键的事件 err 3 错误事件 warning 4 警告事件 notice 5 普通但重要的事件 info 6 有用的信息 debug 7 调试信息
listen web_port
bind 127.0.0.1:80
mode http
log global #开启当前web_port的日志功能,默认不记录日志
server web1 127.0.0.1:8080 check inter 3000 fall 2 rise 5
# systemctl restart haproxy
Rsyslog配置
[root@localhost ~]# vim /etc/rsyslog.conf
ModLoad imudpUDPServerRun 514
......
local7.* /var/log/boot.log
local2.* /var/log/haproxy.log
......
# systemctl restart rsyslog
#systemctl restart haproxy
验证HAProxy日志
[root@localhost ~]# tail -f /var/log/haproxy.log
Aug 14 20:21:06 localhost haproxy[18253]: Connect from 192.168.0.1:3050 to 10.0.0.7:80 (web_host/HTTP)
Aug 14 20:21:06 localhost haproxy[18253]: Connect from 192.168.0.1:3051 to 10.0.0.7:80 (web_host/HTTP)
Aug 14 20:21:06 localhost haproxy[18253]: Connect from 192.168.0.1:3050 to 10.0.0.7:80 (web_host/HTTP)
Proxies配置
defaults [
默认配置项,针对以下的frontend、backend和listen生效,可以多个name也可以没有name
frontend
前端servername,类似于Nginx的一个虚拟主机 server和LVS服务集群。
backend
后端服务器组,等于nginx的upstream和LVS中的RS服务器
listen
将frontend和backend合并在一起配置,相对于frontend和backend配置更简洁,生产常用
注意:name字段只能使用大小写字母,数字,‘-’(dash),’_‘(underscore),’.’ (dot)和 ‘:'(colon),并且严格区分大小写

Proxies配置-defaults
defaults 配置参数
```bash
option redispatch #当server Id对应的服务器挂掉后,强制定向到其他健康的服务器,重新派发
</code></pre>
option abortonclose #当服务器负载很高时,自动结束掉当前队列处理比较久的连接,针对业务情况选择开启
option http-keep-alive #开启与客户端的会话保持
option forwardfor #透传客户端真实IP至后端web服务器
mode http|tcp #设置默认工作类型,使用TCP服务器性能更好,减少压力,四层七层
timeout http-keep-alive 120s #session 会话保持超时时间,此时间段内会转发到相同的后端服务器
timeout connect 120s #客户端请求从haproxy到后端server最长连接等待时间(TCP连接之前),默认单位ms
timeout server 600s #客户端请求从haproxy到后端服务端的请求处理超时时长(TCP连接之后),默认单位ms,如果超时,会出现502错误,此值建议设置较大些,访止502错误
timeout client 600s #设置haproxy与客户端的最长非活动时间,默认单位ms,建议和timeout server相同
timeout check 5s #对后端服务器的默认检测超时时间
default-server inter 1000 weight 3 #指定后端服务器的默认设置
```
Proxies配置-frontend
frontend 配置参数
```bash
bind: #指定HAProxy的监听地址,可以是IPV4或IPV6,可以同时监听多个IP或端口,可同时用于listen字段中
</code></pre>
#格式:
bind [
<
address>]:<port_range> [, ...] [param*]
#注意:如果需要绑定在非本机的IP,需要开启内核参数:net.ipv4.ip_nonlocal_bind=1
```
范例:
```bash
listen http_proxy #监听http的多个IP的多个端口和sock文件
bind :80,:443,:8801-8810
bind 10.0.0.1:10080,10.0.0.1:10443
bind /var/run/ssl-frontend.sock user root mode 600 accept-proxy
listen http_https_proxy #https监听
bind :80
bind :443 ssl crt /etc/haproxy/site.pem #公钥和私钥公共文件
listen http_https_proxy_explicit #监听ipv6、ipv4和unix sock文件
bind ipv6@:80
bind ipv4@public_ssl:443 ssl crt /etc/haproxy/site.pem
bind unix@ssl-frontend.sock user root mode 600 accept-proxy
listen external_bind_app1 #监听file descriptor
bind "fd@${FD_APP1}"
```
生产示例
```bash
frontend web_port #可以采用后面形式命名:业务-服务-端口号
bind :80,:8080
bind 10.0.0.7:10080,:8801-8810,10.0.0.17:9001-9010
mode http|tcp #指定负载协议类型
use_backend <backend_name> #调用的后端服务器组名称
```
Comments NOTHING